
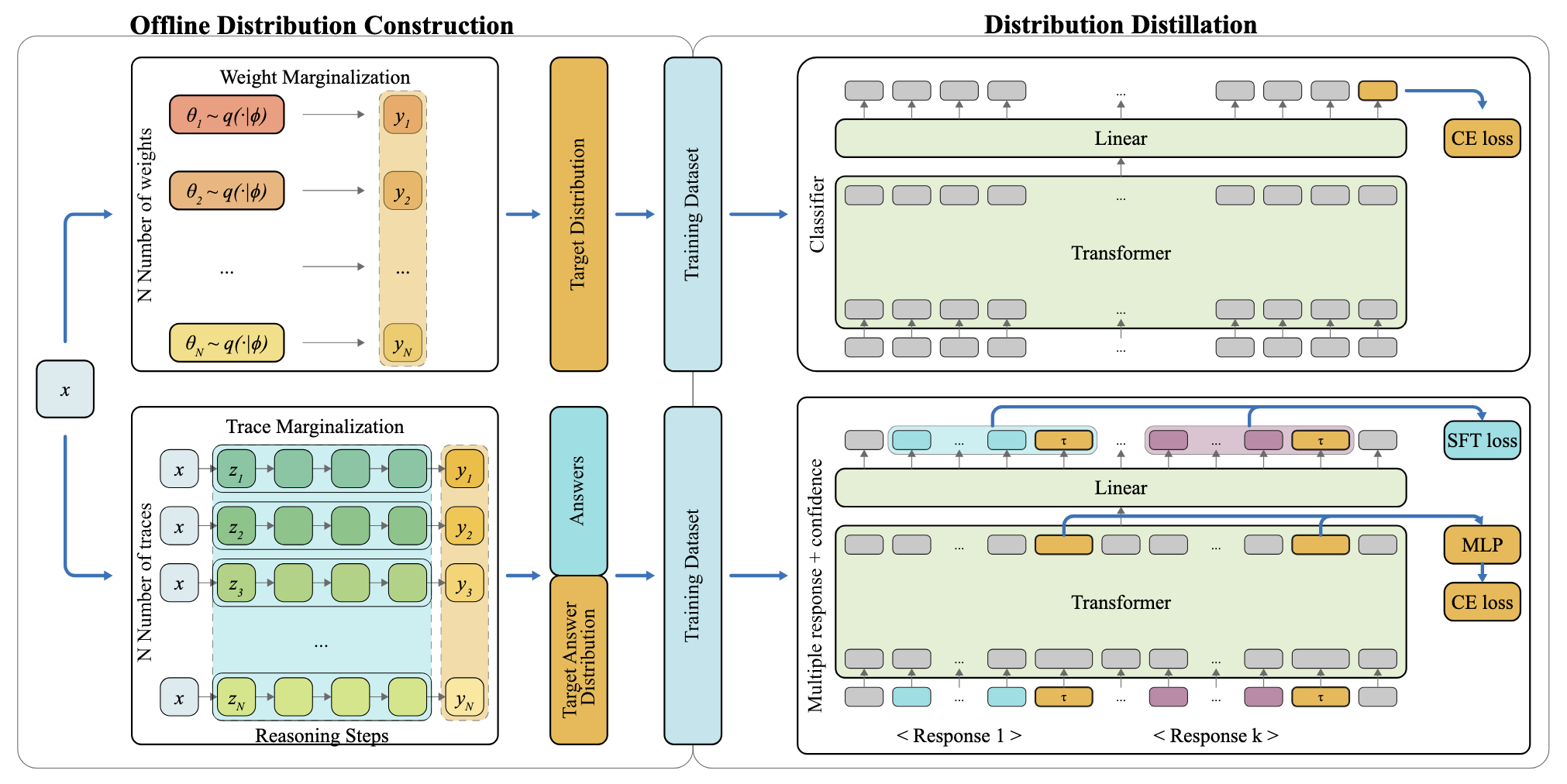
Dist2ill: Distributional Distillation for One-Pass Uncertainty Estimation in Large Language Models
Yicong Zhao*, King Yeung Tsang*, Harshil Vejendla, Haizhou Shi, Zhuohang Li, Zhigang Hua, Qi Xu, Tunyu Zhang, Yi Wang, Ligong Han, Bradley A. Malin, Hao Wang
Preprint
TLDR: We address the mismatch between LLM answer quality and confidence by distilling Bayesian uncertainty—normally requiring costly test-time sampling—into a single forward pass. Our distributional distillation framework trains an LLM to generate multiple diverse reasoning paths at once and uses a lightweight module to approximate empirical confidence from the induced distribution.
[paper] [code]
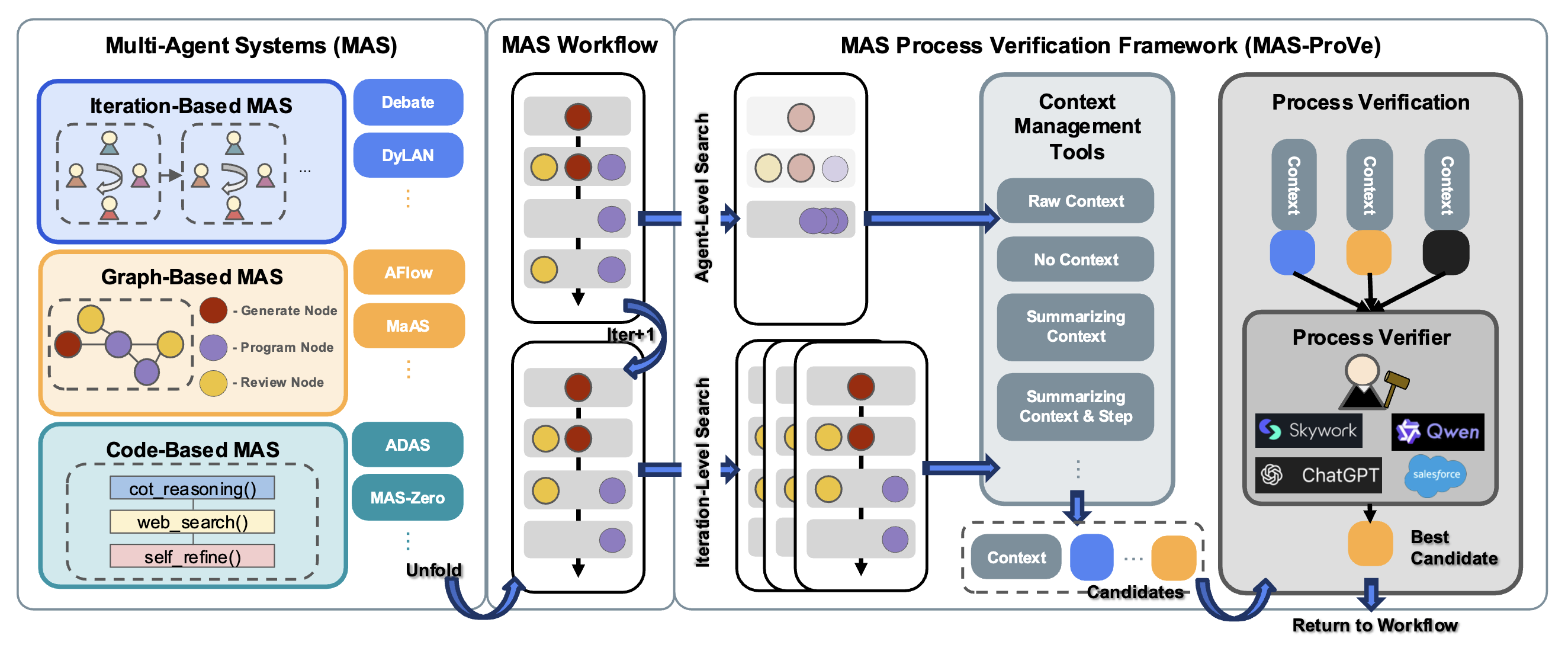
MAS-ProVe: Understanding the Process Verification of Multi-Agent Systems
Vishal Venkataramani, Haizhou Shi, Zixuan Ke, Austin Xu, Xiaoxiao He, Yingbo Zhou, Semih Yavuz, Hao Wang, Shafiq Joty
Preprint
TLDR: We develop a framework and conduct a comprehensive empirical study of process verification in multi-agent LLM systems. Overall, we show that robust and effective process verification for MAS remains an open challenge beyond current paradigms.
[paper] [code]
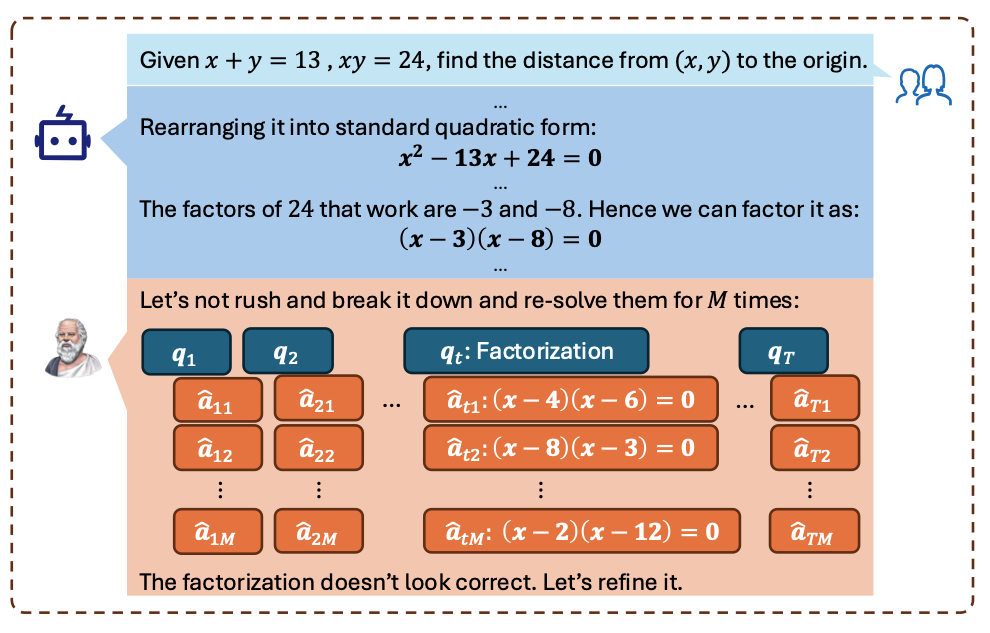
SSR: Socratic Self-Refine for Large Language Model Reasoning
Haizhou Shi, Ye Liu, Bo Pang, Zeyu Leo Liu, Hao Wang, Silvio Savarese, Caiming Xiong, Yingbo Zhou, Semih Yavuz
Preprint
TLDR: We introduce Socratic Self-Refine (SSR), a fine-grained test-time reasoning framework that decomposes model outputs into verifiable sub-steps, identifies unreliable reasoning through targeted re-solving and consistency checks, and iteratively refines errors to produce more accurate and interpretable solutions, achieving consistent gains over prior self-refinement methods across multiple benchmarks and models.
[paper] [code]
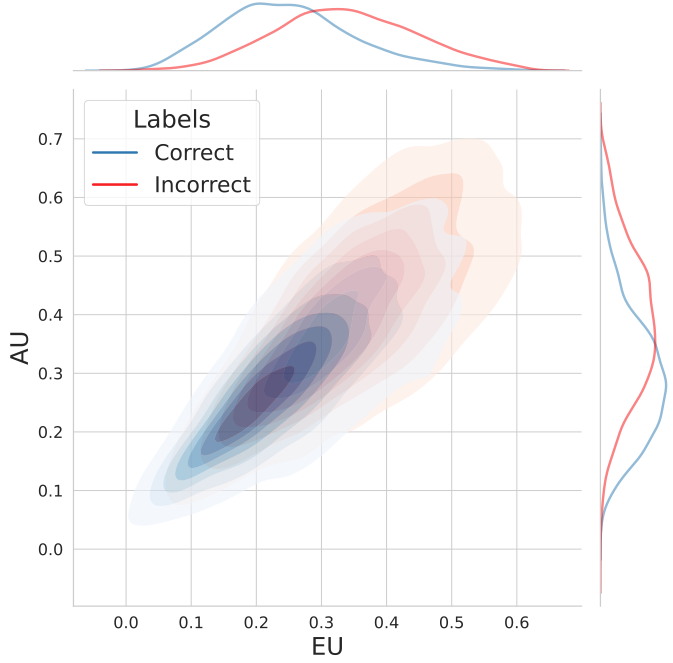
TokUR: Token-Level Uncertainty Estimation for Large Language Model Reasoning
Tunyu Zhang*, Haizhou Shi*, Yibin Wang, Hengyi Wang, Xiaoxiao He, Zhuowei Li, Haoxian Chen, Ligong Han, Kai Xu, Huan Zhang, Dimitris Metaxas, Hao Wang
Fourteenth International Conference on Learning Representations (ICLR), 2026.
TLDR: We introduce TokUR, a method for estimating response-level uncertainty in Large Language Model reasoning without additional training. TokUR works by injecting low-rank weight perturbations within certain constraints, achieving better performance in dehallucination detection and test-time scaling compared to existing methods.
[paper] [code]
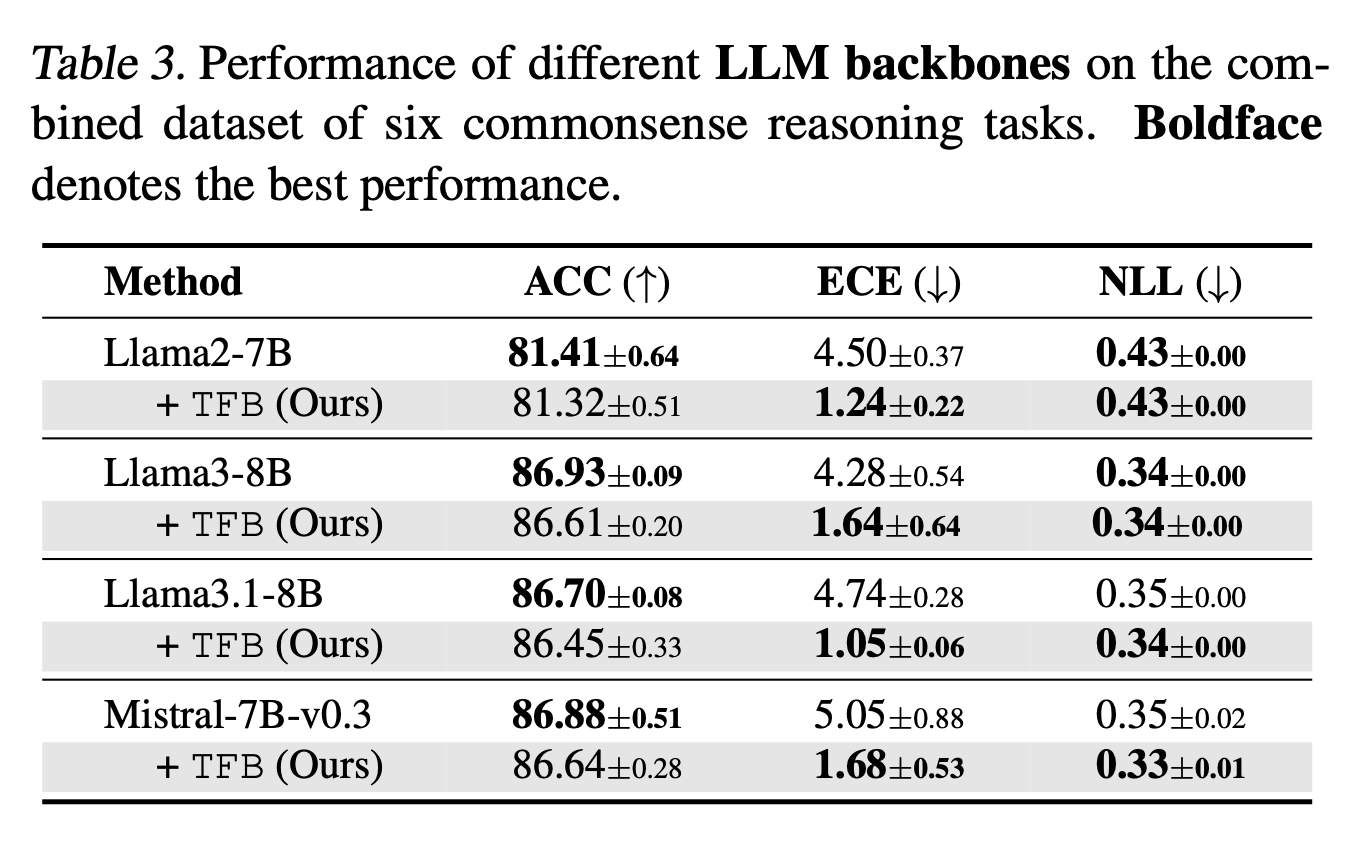
Training-Free Bayesianization for Low-Rank Adapters of Large Language Models
Haizhou Shi*, Yibin Wang*, Ligong Han, Huan Zhang, Hao Wang
Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS), 2025.
TLDR: We introduce Training-Free Bayesianization (TFB), a method that converts existing LoRA adapters into Bayesian models without requiring additional training to estimate uncertainty in Large Language Models. TFB works by searching for optimal variance in the weight posterior within certain constraints, which we prove is equivalent to variational inference under certain conditions.
[paper] [code]
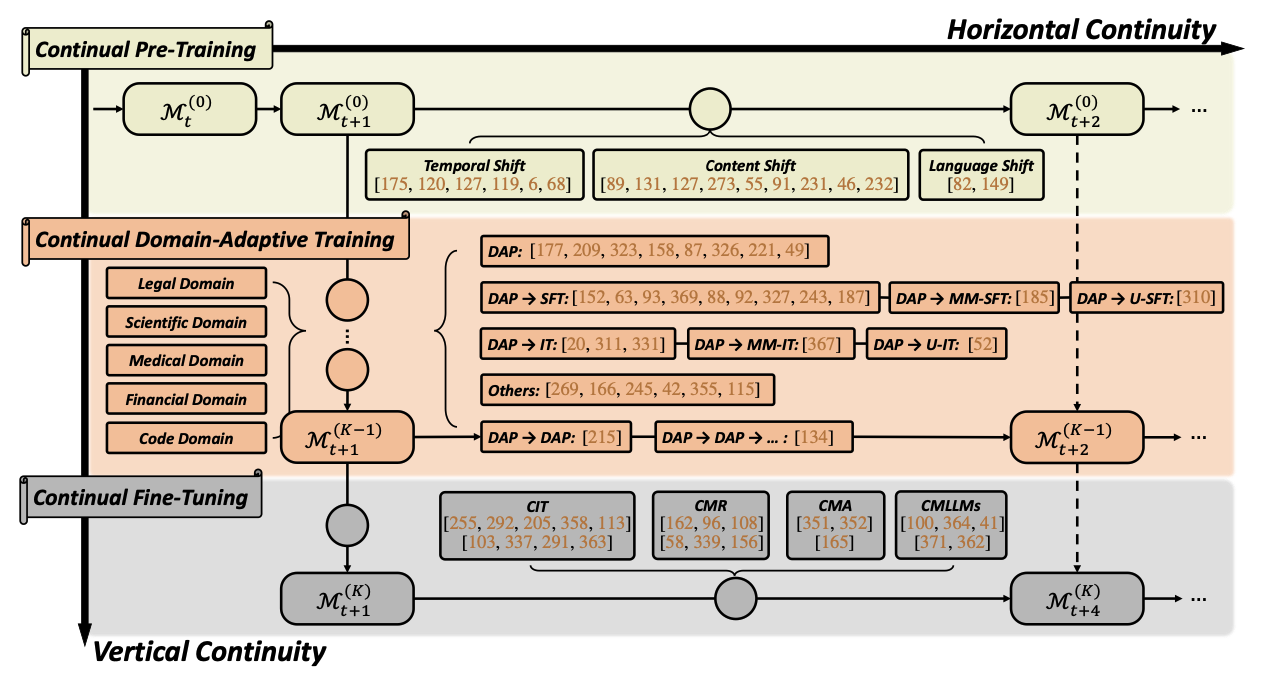
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, Hao Wang
ACM Computing Surveys, 2025.
TLDR: In this paper, we provide a comprehensive review of the past, present, and future of Continual Learning and its application to LLMs, enabling them to adapt to ever-changing envorinments in an efficient and reliable way.
[paper] [code]
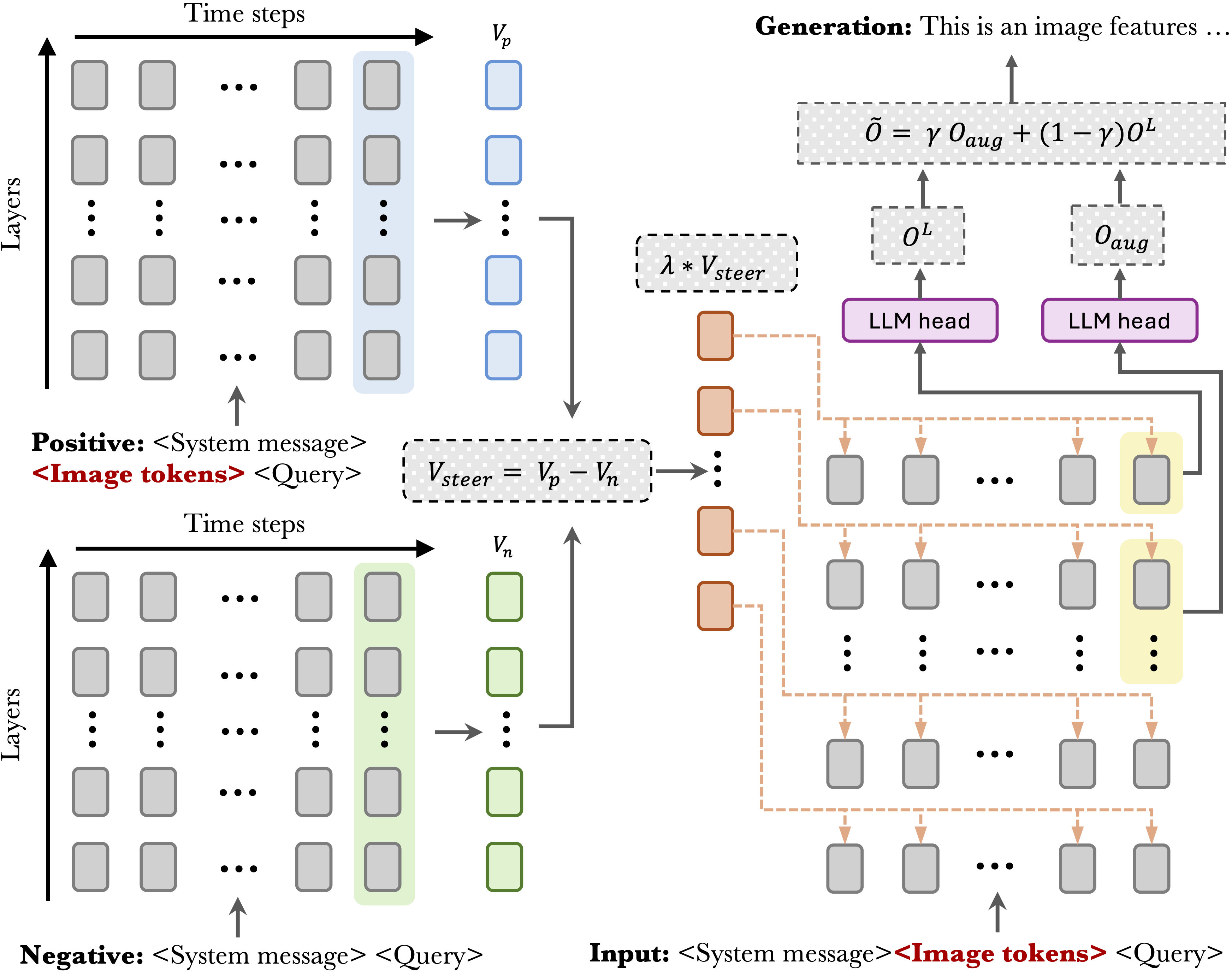
The Hidden Life of Tokens: Reducing Hallucination of Large Vision-Language Models via Visual Information Steering
Zhuowei Li, Haizhou Shi, Yunhe Gao, Di Liu, Zhenting Wang, Yuxiao Chen, Ting Liu, Long Zhao, Hao Wang, and Dimitris N. Metaxas
Forty-Second International Conference on Machine Learning (ICML), 2025.
TLDR: We examined how Large Vision-Language Models (LVLMs) process visual and textual information, discovering they gradually lose visual context during generation. Based on these insights, we developed VISTA, a training-free framework that reinforces visual information and leverages early layer activations to reduce hallucinations by approximately 40%. Our method outperforms existing approaches across multiple benchmarks and architectures, working with various decoding strategies without requiring extra supervision.
[paper] [code]

Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal LLMs
Hengyi Wang, Haizhou Shi, Shiwei Tan, Weiyi Qin, Wenyuan Wang, Tunyu Zhang, Akshay Nambi, Tanuja Ganu, Hao Wang
Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), 2025.
TLDR: We discuss the MMNeedle benchmark, a new tool for evaluating how well Multimodal Large Language Models (MLLMs) handle long-context tasks. The benchmark tests MLLMs' ability to find specific sub-images within larger image sets based on text instructions. Using techniques like image stitching, it creates longer visual contexts for testing.
[paper] [code]
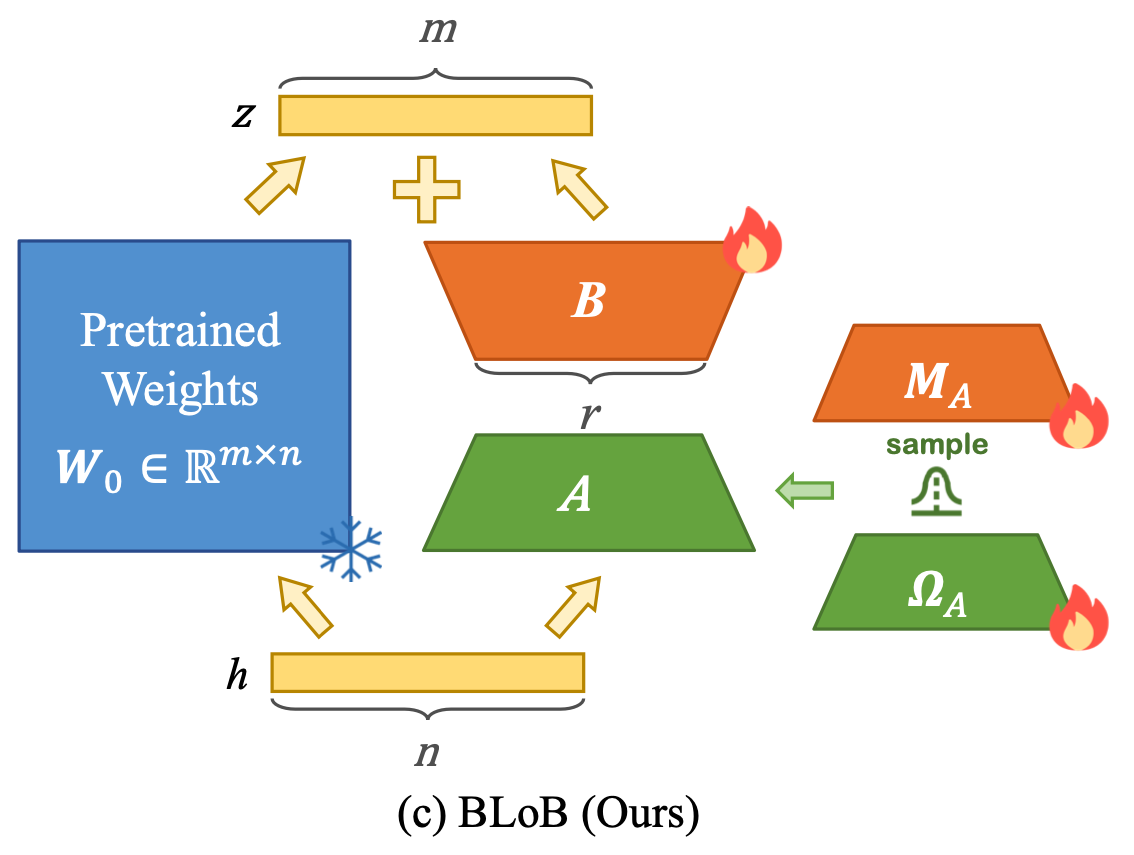
BLoB: Bayesian Low-Rank Adaptation by Backpropagation for Large Language Models
Yibin Wang*, Haizhou Shi*, Ligong Han, Dimitris Metaxas, Hao Wang
Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024.
TLDR: We propose a Bayesian Low-Rank Adaptation framework for LLMs that continuously and jointly adjusts both the mean and covariance of LLM parameters throughout the whole fine-tuning process, which effectively alleviates the problem of LLMs' overconfidence.
[paper] [code] [slides] [talk]
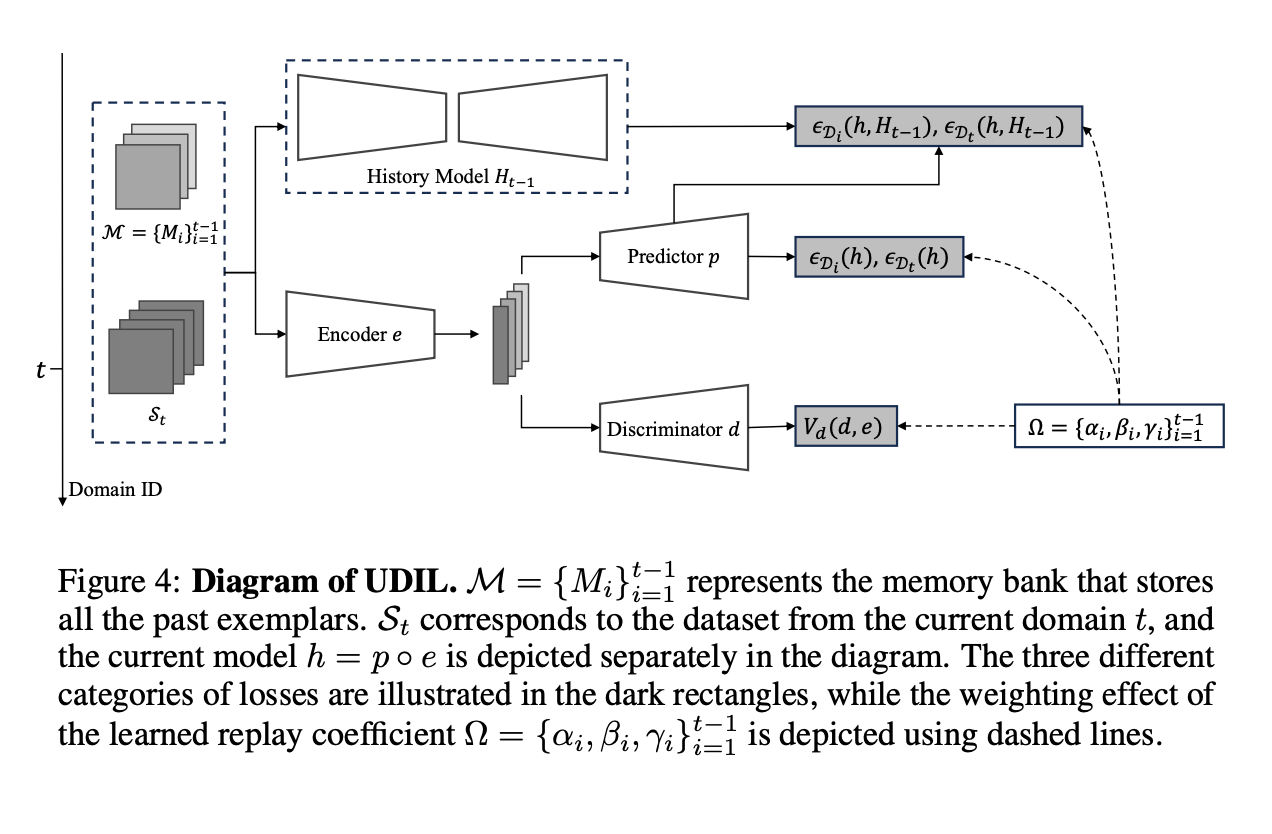
A Unified Approach to Domain Incremental Learning with Memory: Theory and Algorithm
Haizhou Shi, Hao Wang
Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS), 2023.
TLDR: A novel theoretical framework, UDIL, is proposed for domain incremental learning, unifying multiple existing methods. The key insight of our study is that UDIL allows for adaptive coefficients during training, yielding a tighter generalization bound compared to its counterparts.
[paper] [code] [slides] [talk]
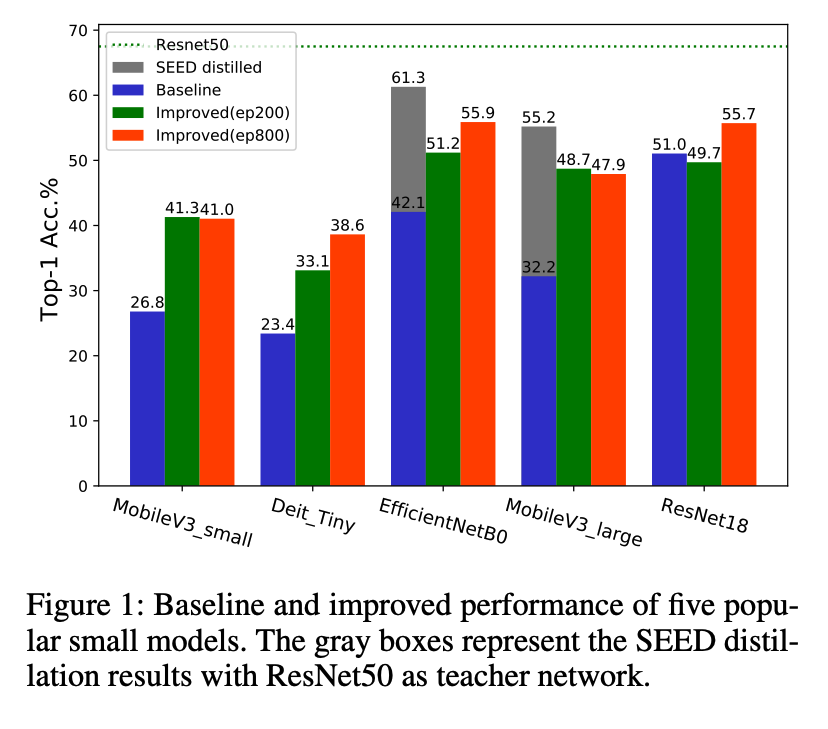
On the Efficacy of Small Self-Supervised Contrastive Models without Distillation Signals
Haizhou Shi, Youcai Zhang, Siliang Tang, Wenjie Zhu, Yaqian Li, Yandong Guo, Yueting Zhuang
Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI), 2022.
TLDR: This paper studies the issue of training self-supervised small models without distillation signals. Key observations about the learned representation distribution are made and several empirical measures addressing the problem are evaluated.
[paper] [code] [slides]
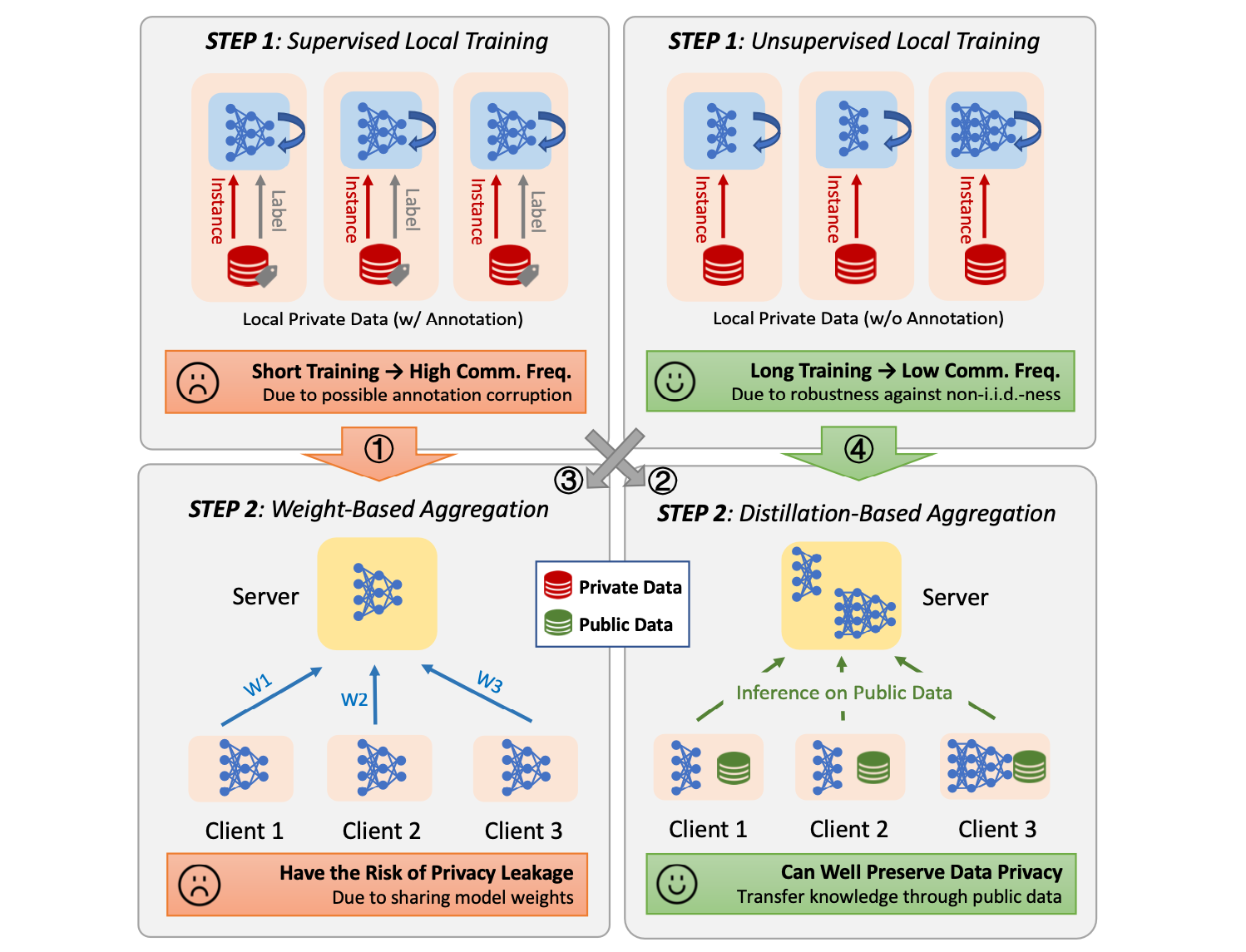
Towards Communication-efficient and Privacy-preserving Federated Representation Learning
Haizhou Shi, Youcai Zhang, Zijin Shen, Siliang Tang, Yaqian Li, Yandong Guo, Yueting Zhuang
International Workshop on Trustable, Verifiable and Auditable Federated Learning in Conjunction with AAAI (FL-AAAI), 2022.
TLDR: Based on the observed robustness against data i.i.d.-ness of contrastive methods, a similarity-based distillation method is used to design a novel federated representation learning framework, FLESD, which is verified to be more communication-efficient and privacy-preserving.
[paper] [code] [talk]
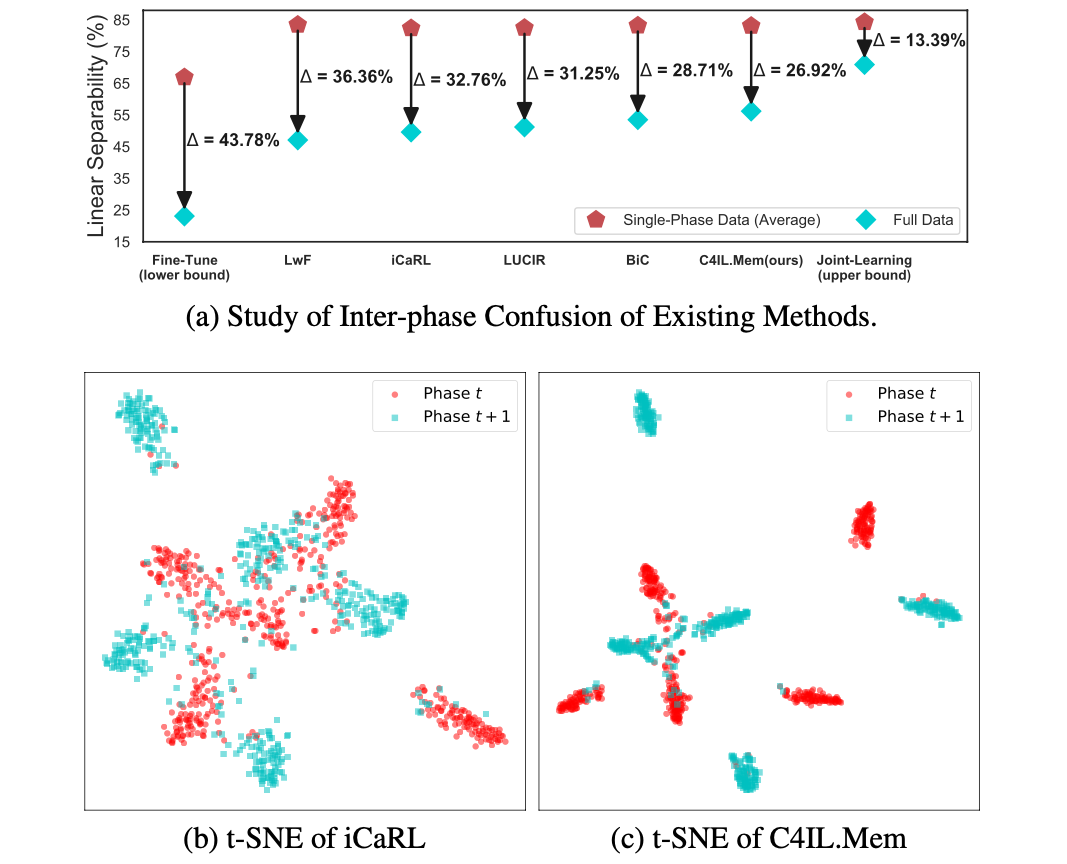
Revisiting Catastrophic Forgetting in Class Incremental Learning
Zixuan Ni*, Haizhou Shi*, Siliang Tang, Longhui Wei, Qi Tian, Yueting Zhuang
Arxiv preprint, 2021.
TLDR: Three causes of catastrophic forgetting in class incremental learning are analysed, based on which a novel framework, C4IL, is proposed to reduce the representational overlaps among different tasks.
[paper] [code]
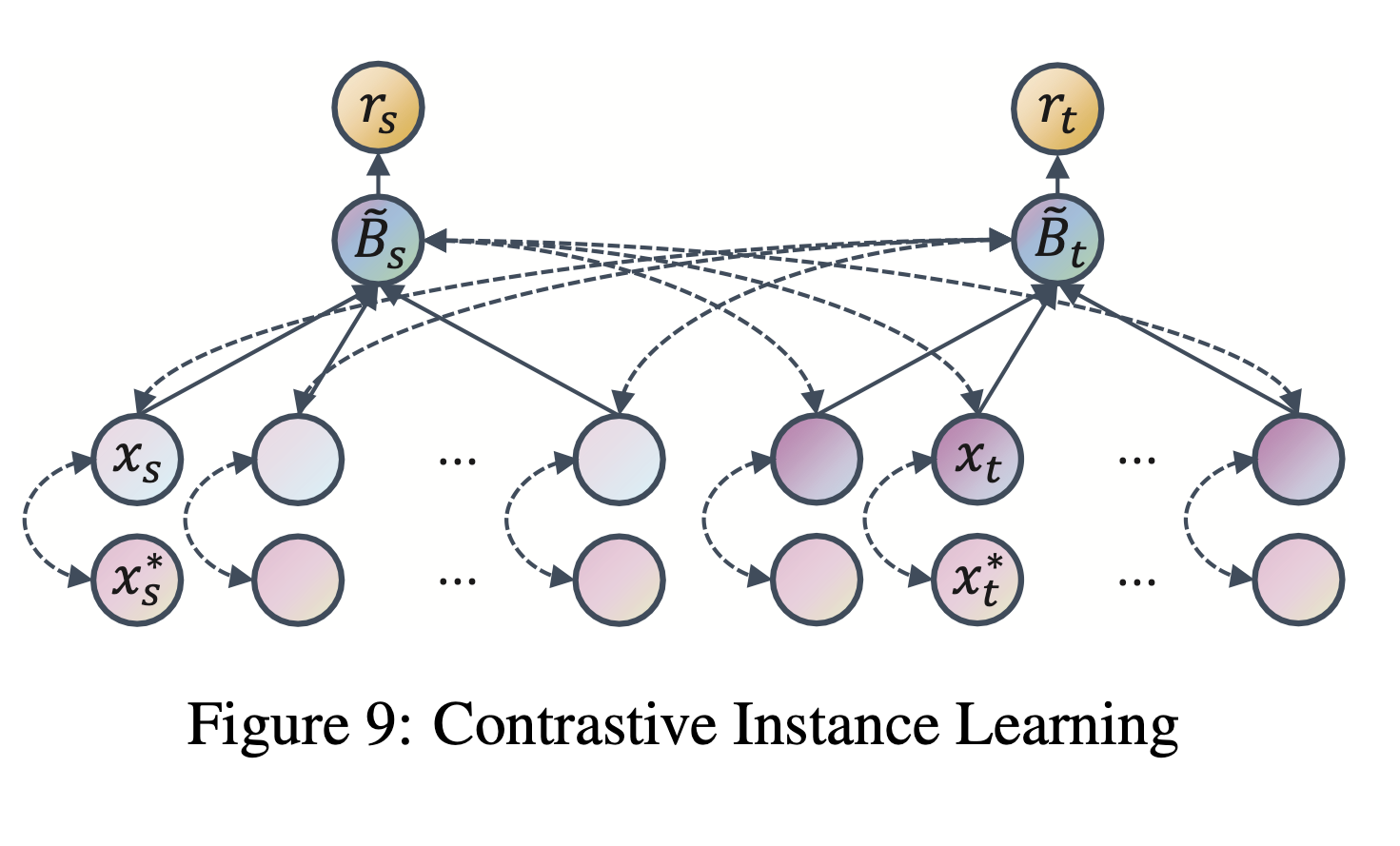
CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction
Tao Chen, Haizhou Shi, Siliang Tang, Zhigang Chen, Fei Wu, Yueting Zhuang
Fifty-Ninth Annual Meeting of the Association of Computational Linguistics (ACL), 2021.
TLDR: This paper goes beyond typical multi-instance learning (MIL) framework and propose a novel contrastive instance learning (CIL) framework for distantly supervised relation extraction. Specifically, we regard the initial MIL as the relational triple encoder and constraint positive pairs against negative pairs for each instance.
[paper] [code]
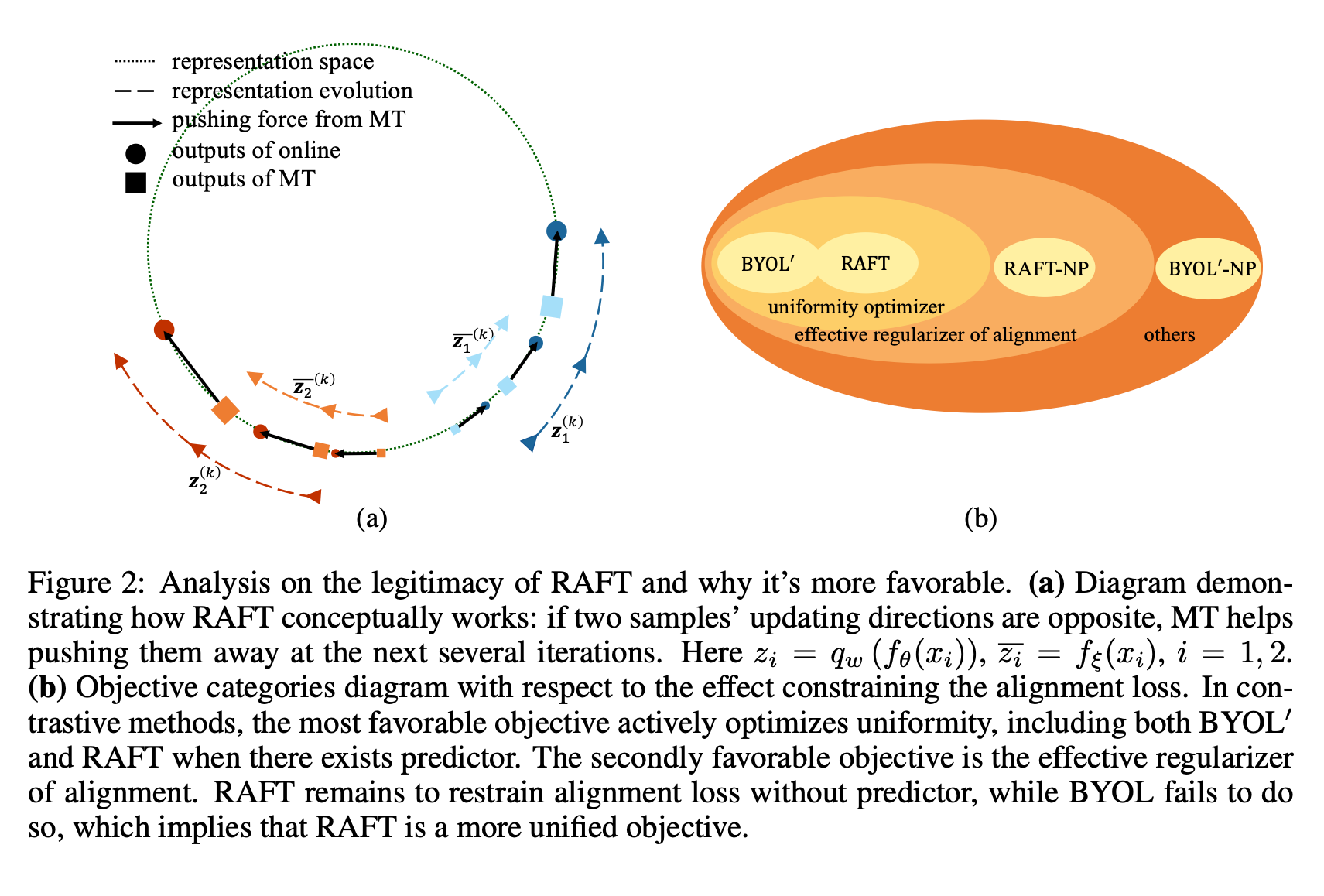
Run Away From your Teacher: Understanding BYOL by a Novel Self-Supervised Approach
Haizhou Shi*, Dongliang Luo*, Siliang Tang, Jian Wang, Yueting Zhuang
Arxiv preprint, 2020.
TLDR: In this paper, we suggest understanding BYOL from the view of our proposed interpretable self-supervised learning framework, Run Away From your Teacher (RAFT). It optimizes two objectives at the same time: (i) aligning two views of the same data and (ii) running away from the model’s Mean Teacher (MT). Theoretical justification is also provided for equating the proposed RAFT and BYOL under certain conditions.
[paper] [code]
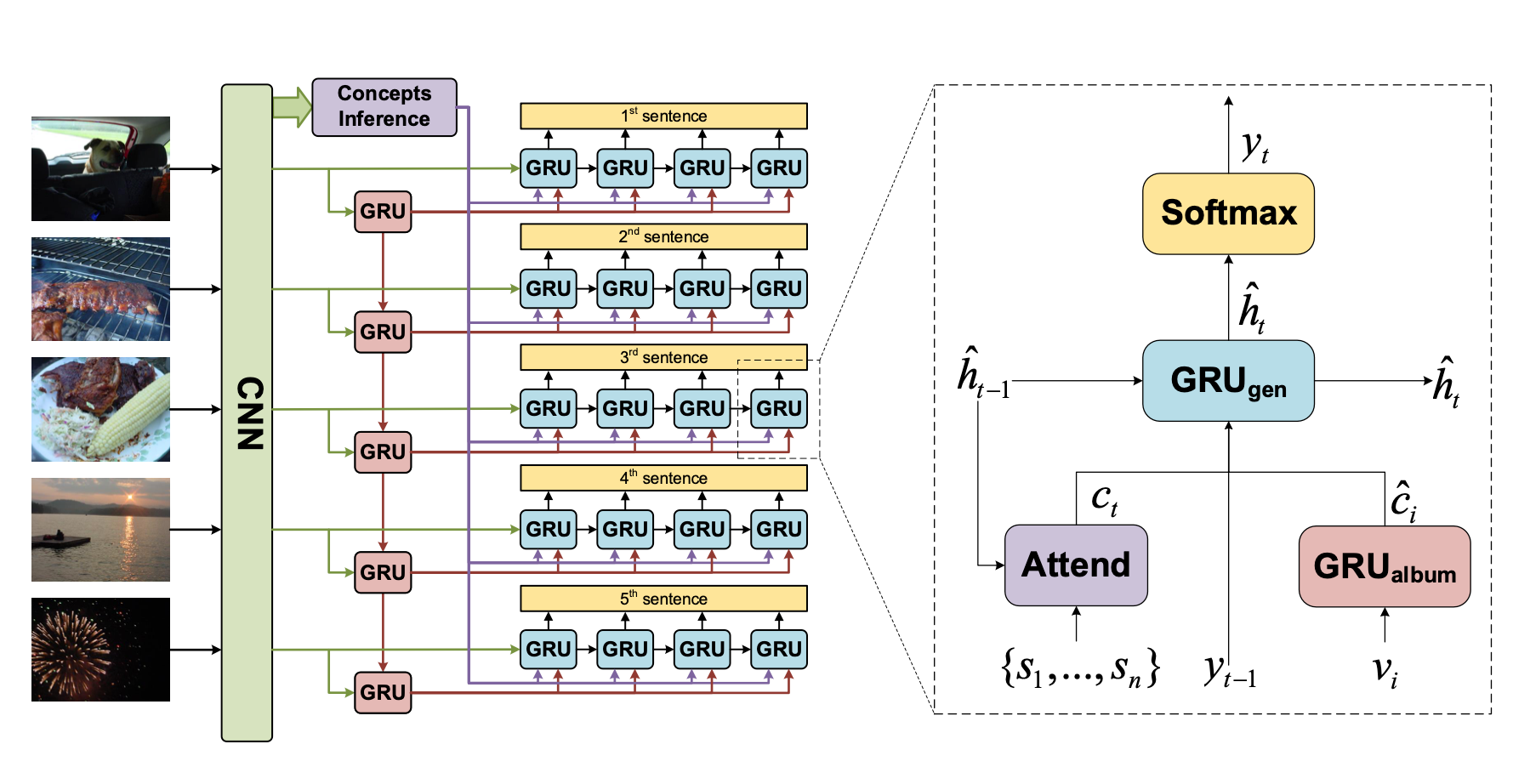
Informative Visual Storytelling with Cross-modal Rules
Jiacheng Li, Haizhou Shi, Siliang Tang, Fei Wu, Yueting Zhuang
Twenty-Seventh ACM International Conference on Multimedia (ACM MM), 2019.
TLDR: To solve problem of generating too-general descriptions in the field of visual storytelling, we propose a method to mine the cross-modal rules to help the model infer these informative concepts given certain visual input.
[paper] [code]